6.千万级数据查询初探
1 开篇明议
昨天一家公司的面试官问了个问题,有2个表就是快递详情表和快递轨迹表,每天有百万个
快递,数据表的每张表少说都不少于千万条,问题是怎么根据用户的id快速查找用户的快递单
和运动轨迹?最好查询时间控制在600毫秒下。
这是一个一对多的关系,就一个快递单子有多个轨迹点。
2 测试机子环境
OS: homestead:8.0.1(debian) 64位
内存 : 8G
mysql version: 5.7.27
2 建表和添加测试数据
create database test; -- 测试数据库
-- 快递订单表
DROP TABLE IF EXISTS `express`;
CREATE TABLE `express` (
`id` int(30) NOT NULL AUTO_INCREMENT,
`uid` char(100) NOT NULL COMMENT '用户id',
`p_from` char(50) NOT NULL COMMENT '发件人',
`p_to` char(50) CHARACTER SET utf8 NOT NULL COMMENT '收件人',
`is_receive` int(1) NOT NULL DEFAULT '0' COMMENT '是否收件 0否 1收',
`create_time` int(10) NOT NULL COMMENT '创建时间戳',
PRIMARY KEY (`id`),
KEY `uid` (`uid`)
) ENGINE=MyISAM AUTO_INCREMENT=1 DEFAULT CHARSET=latin1;
--- 轨迹表
CREATE TABLE `track` (
`id` int(255) NOT NULL AUTO_INCREMENT,
`y` float(10,0) DEFAULT NULL COMMENT 'y座标',
`x` float(10,0) DEFAULT NULL COMMENT 'x座标',
`express_id` int(22) DEFAULT NULL COMMENT '单号',
PRIMARY KEY (`id`),
KEY `order_number` (`express_id`)
) ENGINE=MyISAM AUTO_INCREMENT=2163031 DEFAULT CHARSET=latin1 COMMENT=' 轨迹表';
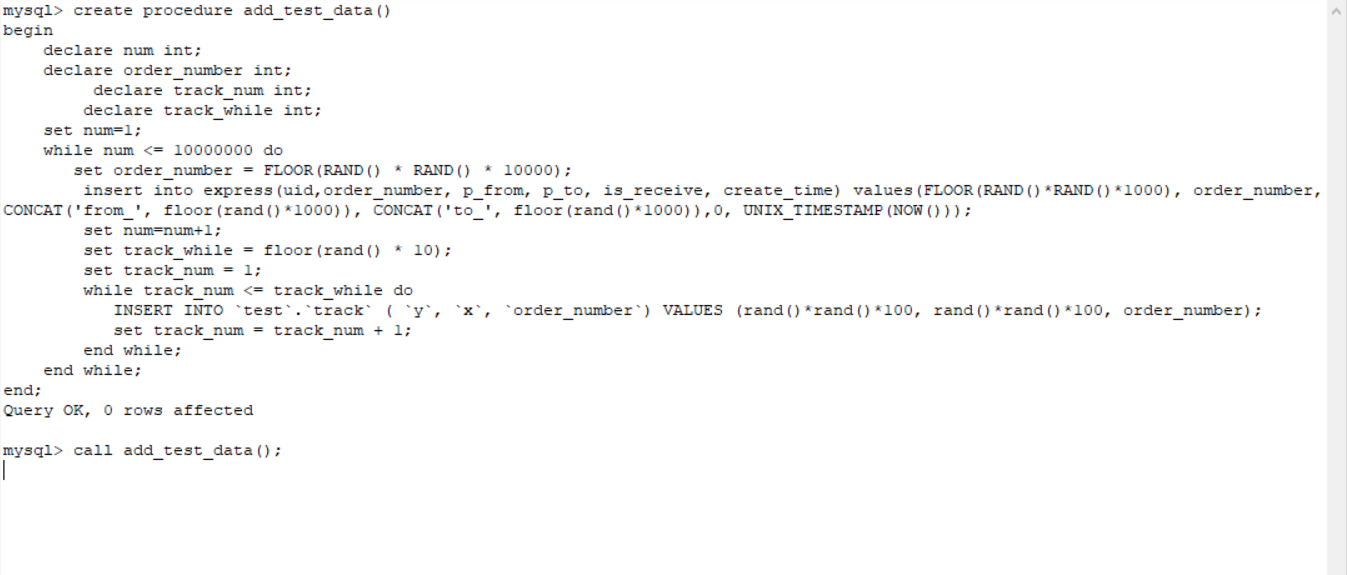
-- 添加测试数据
create procedure add_test_data()
begin
declare num int;
declare order_number int;
declare track_num int;
declare track_while int;
set num=1;
while num <= 10000000 do
insert into express(uid, p_from, p_to, is_receive, create_time) values(replace(uuid(), '-', ''), CONCAT('from_', floor(rand()*1000)), CONCAT('to_', floor(rand()*1000)),0, UNIX_TIMESTAMP(NOW()));
set num=num+1;
set track_while = floor(rand() * 10);
set track_num = 1;
while track_num <= track_while do
INSERT INTO `test`.`track` ( `y`, `x`, `express_id`) VALUES (rand()*rand()*100, rand()*rand()*100, (select max(id)from express));
set track_num = track_num + 1;
end while;
end while;
end;
-- 导入
call add_test_data();
tip
有1亿条左右的数据,预计没有半天时间是生成不完的。
tip
由于innodb要额外处理事务的索引,相对来说MyISAM 更快
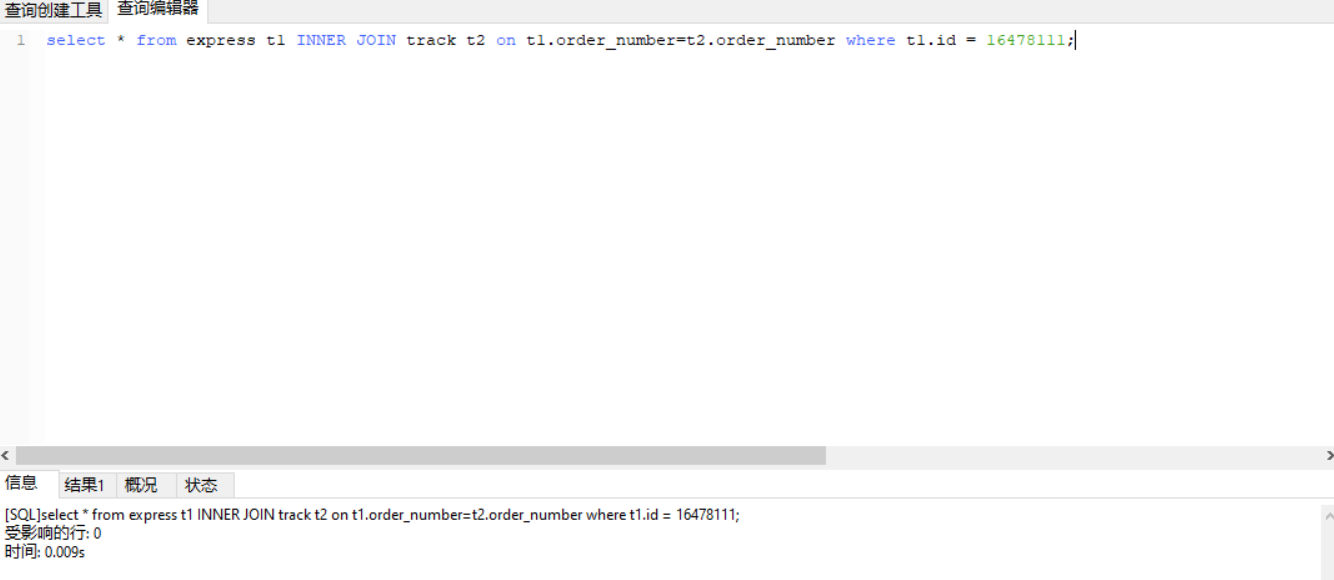
从结果来说,主键联表查找有1千8百多万条数据表,和1亿多条的详情表中查询的速度是很快的。
tip
回到原来的问题,根据用户id即uid在千万条快递单子和上亿的轨迹查找用户的快递和快递详情。
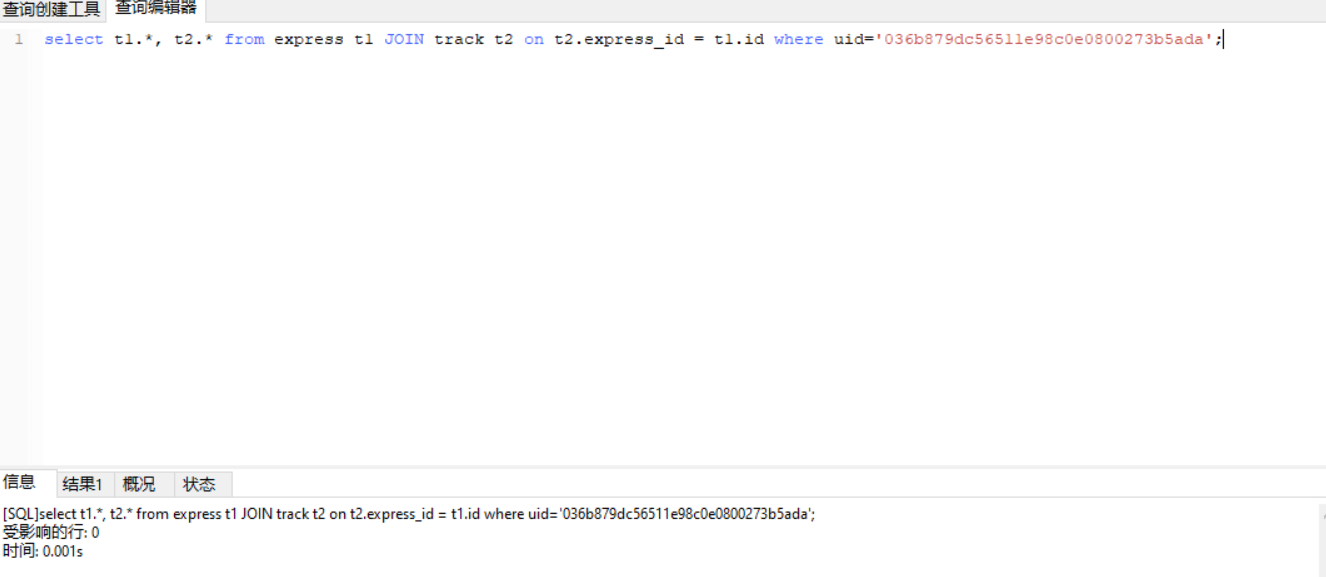
结果是:0.001s.
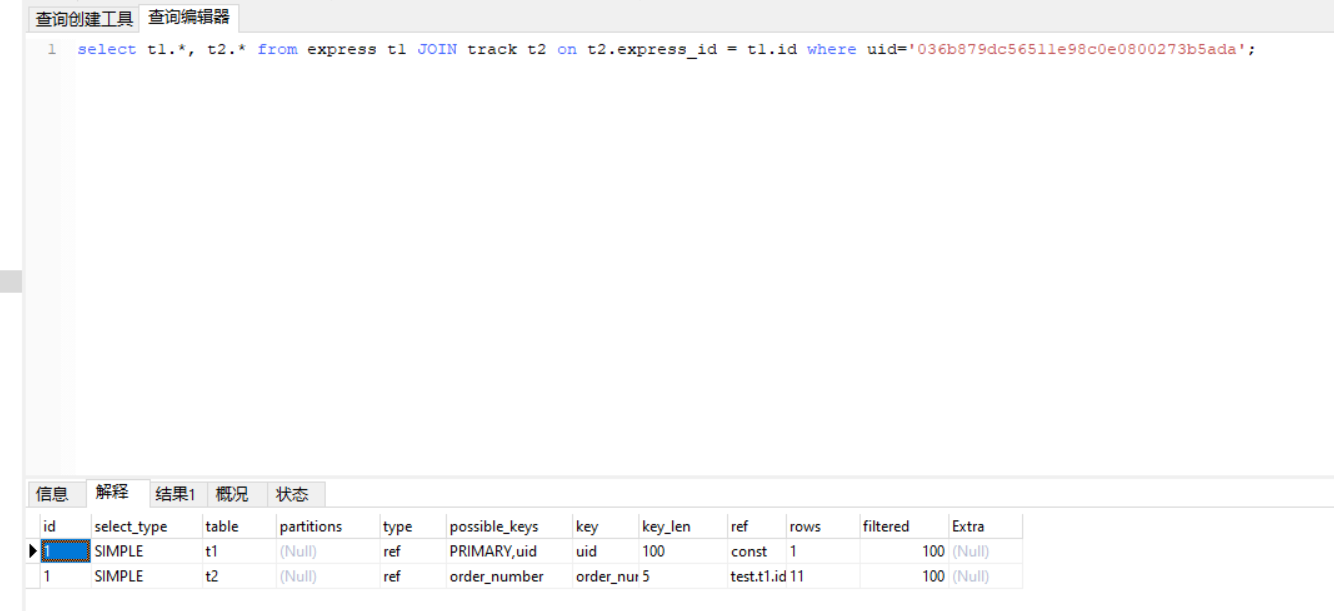
由于索引的起作用,仅扫描1到11行的数据。